-
성능 개선을 진행해보자3스프링 2024. 7. 17. 00:55
Paging 적용하기
성능을 좀 더 올리고 싶었는데 프론트 개발자와 협의 하에 페이징을 적용하기로 하였다.
위에서 적용하고자하는 JPA 의 DTO 직접 조회보다 더 깔끔하게 처리할 수 있다.public Page<AllBookMarkResponseDto> findAllByOrderByModifiedDateDesc(Pageable pageable) { QueryResults<AllBookMarkResponseDto> result = queryFactory .select(Projections.fields(AllBookMarkResponseDto.class, bookMark.id.as("id"), bookMark.modifiedDate.as("date"))) .from(bookMark) .orderBy(bookMark.modifiedDate.desc()) .offset(pageable.getOffset()) .limit(pageable.getPageSize()) .fetchResults(); return new PageImpl<>(result.getResults(), pageable, result.getTotal()); }repository계층에서 페이징 쿼리를 사용하였다.
그러나 이 정보를 그대로 사용할 수 없다.
API 스펙에 맞추어야 하기 때문에 이를 또 다른 DTO로 재변환 시켜야 했다.성능을 테스트해보면

전보다 훨씬 나아진 성능을 볼 수 있다.
Count 개선하기
해당 쿼리는 요청이 들어오면 위의 쿼리로 동시에 count쿼리가 나가게 된다.
count쿼리는 정렬이 따로 필요가 없기 때문에 좀 더 효율적인 방식을 구현하려고 한다.@Override public Page<AllBookMarkResponseDto> findAllByOrderByModifiedDateDesc(Pageable pageable) { List<AllBookMarkResponseDto> result = queryFactory .select(Projections.fields(AllBookMarkResponseDto.class, bookMark.id.as("id"), bookMark.modifiedDate.as("date"))) .from(bookMark) .orderBy(bookMark.modifiedDate.desc()) .offset(pageable.getOffset()) .limit(pageable.getPageSize()) .fetch(); JPAQuery<BookMark> countQuery = queryFactory .select(bookMark) .from(bookMark); return PageableExecutionUtils.getPage(result, pageable, countQuery::fetchCount); }count쿼리를 분리하였다.
PageableExecutionUtils를 통해 count쿼리가 필요한 경우라면 countQuery로 정의한 쿼리를 실행한다.
위의 쿼리는 미리 생성한 인덱스를 타고가므로 더 빠른 조회가 가능해진다.
후반 페이지는 offset이 길어질 수록 이전의 범위를 모두 찾아사 조회하므로 원래 250ms까지 성능이 발생했는데,
위와같이 성능이 절반정도 향상이 되었다는 것을 볼 수 있다.count 캐싱하기

원리는 다음과 같다.
첫 조회시에 전체 페이지 전체의 Count를 클라이언트에게 보내고, 그 값은 전달받은 클라이언트는 이후의 페이지 요청마다
count를 보내게 된다.count를 받은 서버는 count값이 null이 아니라면 count 쿼리를 날리지 않게되어 더 효율적인 조회가 가능해진다.
public Page<AllBookMarkResponseDto> findAllByOrderByModifiedDateDesc(Pageable pageable, Long count) { List<AllBookMarkResponseDto> result = queryFactory .select(Projections.fields(AllBookMarkResponseDto.class, bookMark.id.as("id"), bookMark.modifiedDate.as("date"))) .from(bookMark) .orderBy(bookMark.modifiedDate.desc()) .offset(pageable.getOffset()) .limit(pageable.getPageSize()) .fetch(); JPAQuery<BookMark> countQuery = queryFactory .select(bookMark) .from(bookMark); long totalCount = Optional.ofNullable(count).orElseGet(countQuery::fetchCount); return new PageImpl<>(result, pageable, totalCount); }count가 requestParam형태로 넘어오게 되는게, null로 넘어오게 된다면 fetchCount()가 실행되어 쿼리를 날리게 되는 구조이다.
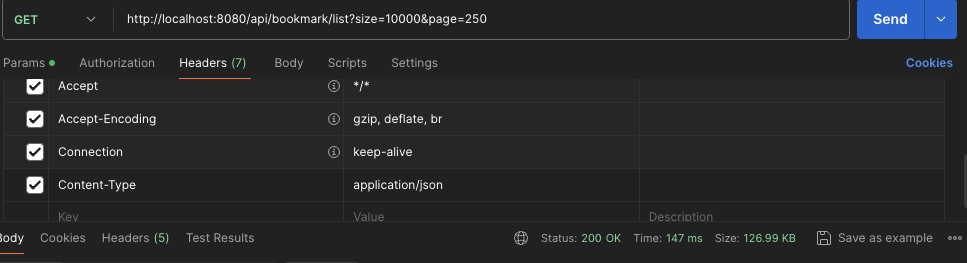
첫 요청시 count를 날릴 때는 147ms의 시간이 나오지만,
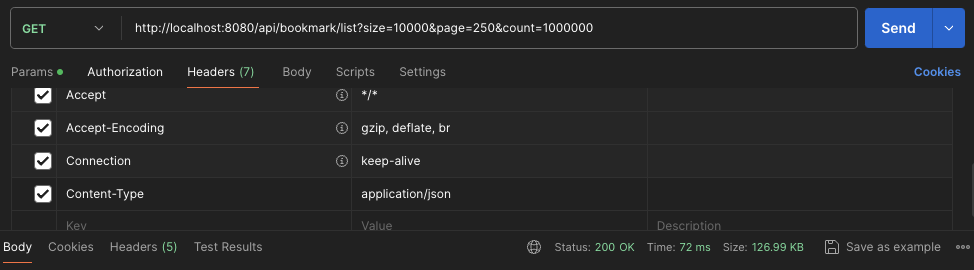
이후 요청에 count를 같이 보내게 된다면, 72ms정도로 성능이 절반정도 향상되는 것을 볼 수 있다.
이 과정들을 거치면서 최초 8s에서 0.072s로 성능이 향상이 된 것을 볼 수 있다.
728x90'스프링' 카테고리의 다른 글
성능 개선을 진행해보자 2 (0) 2024.07.07 성능 개선을 진행해보자 1편 (0) 2024.07.03 빈 등록과 주입을 아라보자 (1) 2024.05.15 [Spring] springBoot2.4 이상에서의 application설정 (0) 2023.12.29 [Spring] Error - Parameter 0 of constructor in ~ required a bean of type 'java.lang....' that could not be found. (0) 2023.12.29