서버 과부하를 아라보자
서버 과부하
서버가 리소스를 소진하여 들어오는 요청을 처리하지 못할 때 발생한다. 이 때 서버는 사용자의 요청을 처리하지 못해 응답 없음이 뜨게된다.
보통 서버의 CPU 사용량이 80, 90%에 도달하면 메모리가 부족하여 계속해서 스와핑이 발생하면 과부하 상태가 된다.
모니터링을 이용한 자원할당
이러한 과부하 분제를 CPU, 메모리, 대역폭과 같은 자원 할당을 수행한다.
모니터링을 하는 이유는 서버 과부하로 인한 서버 중지에 대한 대처가 가능하기 때문이다. 어떤 페이지 요청에 트래픽이 얼마나 발생했는지 등을 모니터링을 통해 파악할 수 있기 때문이다.
AWS 오토스케일링을 이용하면 cloudWatch가 계혹해서 모니터링을 진행하여 서버 대수를 자동으로 늘려주는 작업을 한다. 또한 netdata를 이용하는 것도 가능하다.
그러나 AWS 오토스케일링은 구성하는시 간이 다소 발생한다.
로드밸런싱
서버 앞단에 로드밸런서를 두어 요청을 분산하는 기법도 많이 사용된다.
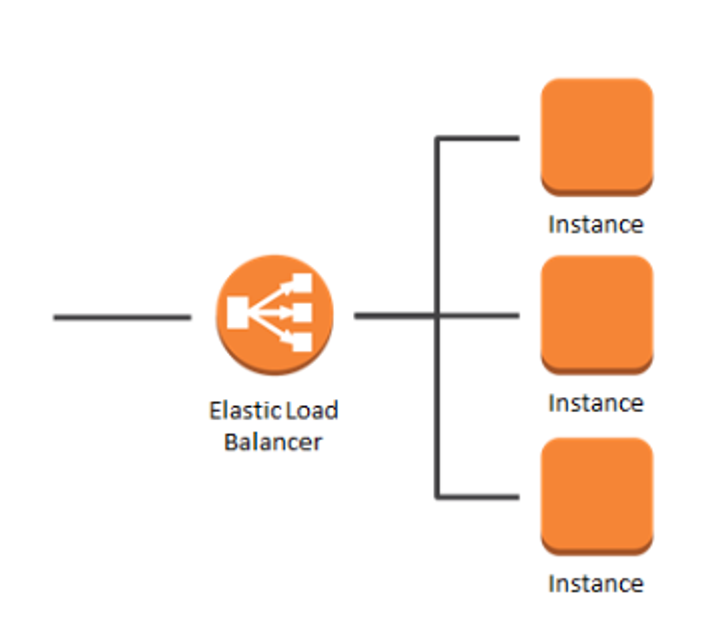
요청을 바로 서버에 넘기는 것이 아니라, 서버를 여러대 증설하고 트래픽을 여러 서버로 전달시킨다.
때에 따라서 로드밸런서에 오토스케일링을 설정하기도 한다.
블랙스완 프로토콜
예측할 수 없는 사고가 일어난 것을 말한다. 즉, 사후에 사고의 원인을 분석하는 것을 말한다.
블랙스완은 어디서 일어날 지 모르기때문에 대비를 해야한다.
예를 들어 구글의 정책은 다음과 같다.
- 영향을 받은 시스템과 각 시스템의 상대적 위험 수준을 확인
- 체계적으로 데이터를 수집하고 원인에 대한 가설을 수립한 후 이를 테스팅
- 잠재적으로 영향을 받을 수 있는 내부의 모든 팀에 연락
- 최대한 빨리 취약점에 영향을 받는 모든 시스템을 업데이트
- 복원계획을 포함한 우리의 대응 과정을 파트너와 고객 등 외부에 전달
서킷 브레이커
서비스 장애를 감지하고 연쇄적으로 생기는 에러를 방지하는 기법.
서비스와 서비스 사이에 서킷브레이커 계층을 두고, 타임아웃 값에 도달하면 그 이후 추가 호출에 무조건 에러를 반환하게 한다.
그냥 무작정 응답이 올 때까지 기다리는것은?? 좋지 않은 방법이다. 사용자 입장에서는 응답을 오래 기다리는 것은 좋은 UX가 아니다. 성공 또는 실패여부는 중요하지 않고 사용자가 기다리지 않아야 하는 것이 중요하다.
서킷브레이커는 closed, open, half_open 의 상태값을 가집니다.
- closed[정상] : 네트워크 요청의 실패율이 임계치보다 낮음
- open[에러] : 임계치이상의 상태를 말합니다. 요청을 서비스로 전송하지 않고 바로 오류를 반환합니다. 이를 fail fast라고 합니다.
- half_open[확인중] : open 상태에서 일정 timeout으로 설정된 시간이 지나면 장애가 해결되었는지 확인하기 위해 half_open 상태로 전환됩니다. 여기서 요청을 전송하여 응답을 확인. 장애가 풀리는지를 확인해서 성공하면 closed, 실패하면 다시 open으로 변경
이와같은 서킷브레이커로 연속적인 에러 발생은 막아주고, 일부 서비스가 종료되더라고 다른 서비스가 이상 없이 동작이 가능하도록 한다.